
Agentic Search: When and Why Should I Use It?
Agentic Search, or Agentic RAG (used interchangeably in this blog post), is an advanced technique that utilizes an LLM to more fluidly control the retrieval step in the answer generation pipeline.
In this post, we’ll dive into how Agentic Search works, where it differs from traditional RAG systems, where it breaks, and how to conceptualize it for your application.
Background
Before we dive in with Agentic Search, let’s quickly walk through the traditional RAG pipeline.
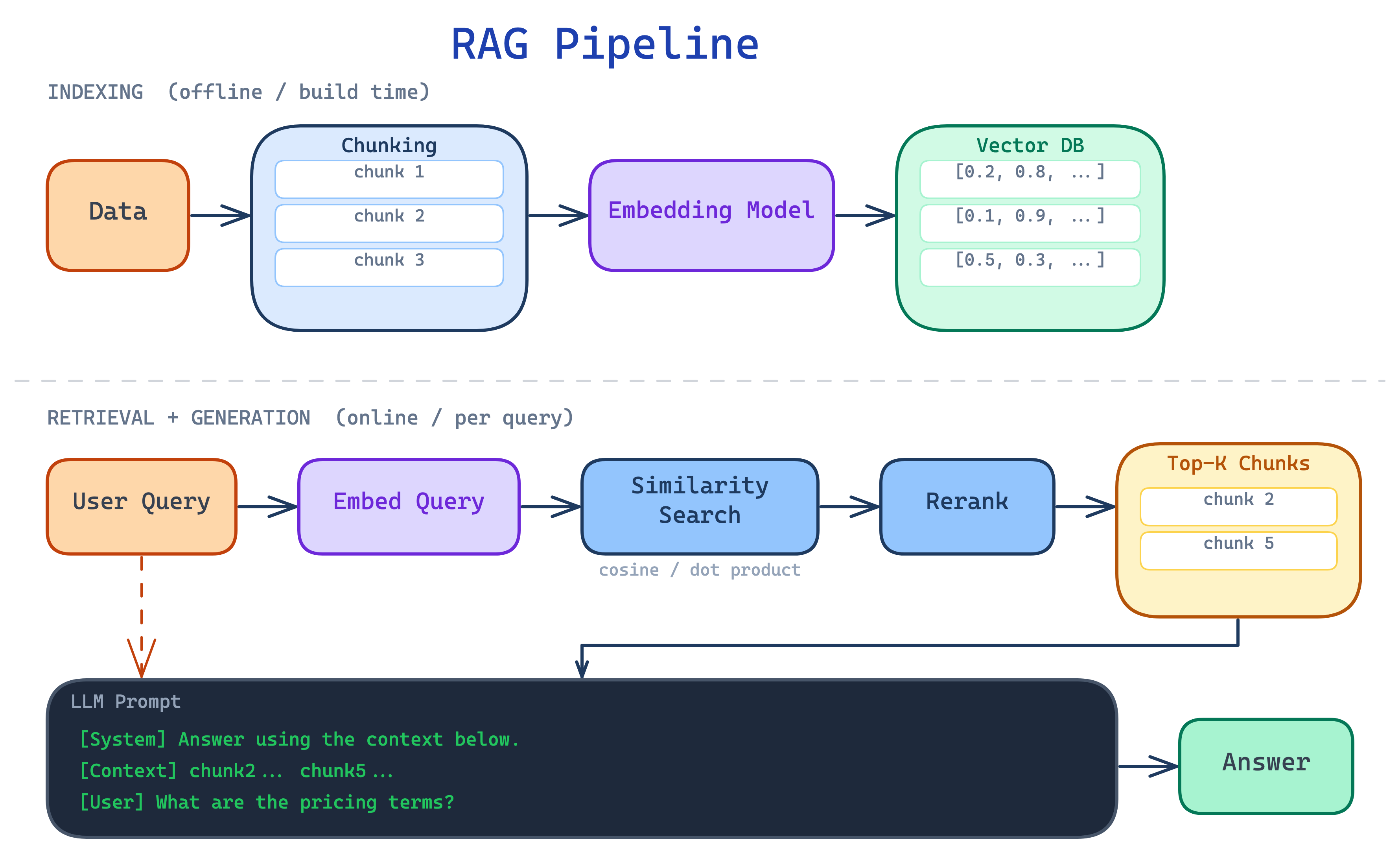
Popularized in 2020 with the paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” by Lewis et al., the traditional RAG pipeline has gotten us quite far since the days of vanilla ChatGPT. RAG fundamentally exploits a simple idea called “in-context learning.”
Crucially, however, the pipeline you see above is static. Because every query—regardless of its nature—goes through the same pipeline, its unable to support queries requiring multi-step reasoning, cross-document comparison, or exhaustive coverage: natural queries in real-world use-cases.
This is where Agentic RAG comes in.
With Agentic RAG, the agent designs its retrieval strategy at query time.
The Architecture of Agentic RAG
We saw in the last section that traditional RAG runs into challenges due to its static nature. With Agentic RAG, this becomes flipped: the pipeline becomes dynamic. Instead of a single-shot pipeline, an AI agent decides what to retrieve, how to evaluate the retrieved items, and whether to search again or stop.
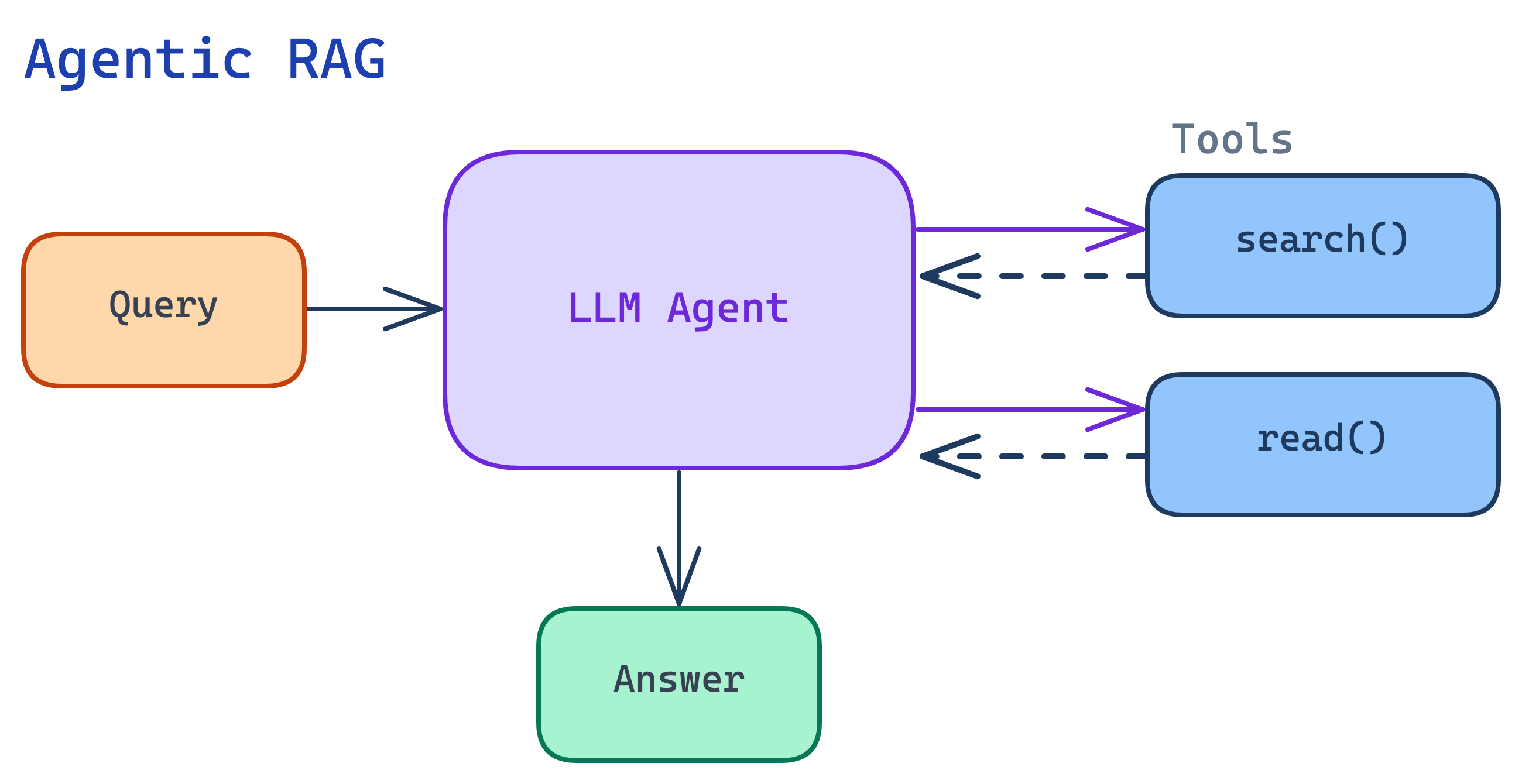
Beautifully, the setup for Agentic RAG is quite simple. An agent only needs one or two tools (search, read) and with a powerful enough model, the process naturally becomes agentic. In fact, this is the exact same architecture that powers deep-research.
Note: three capabilities that make this “agentic”:
-
Query planning. The agent is able to decompose complex questions into sub-queries. For example, a query like “How do our pricing terms compare across the Acme and Globex contracts?” becomes three sub-queries: (1) find pricing terms in the Acme contract, (2) find pricing terms in the Globex contract, (3) compare the two.
-
Iterative retrieval. The agent can now search multiple times, refining its approach based on what it finds. Say it searches for “indemnification clause in Acme contract” and gets back generic insurance boilerplate. The agent then reformulates this to “liability and hold harmless provisions in Acme MSA” and finds the actual clause.
-
Self-evaluation. The agent now assesses its own stopping condition. It decides if it has enough information to answer the question. Say it’s asked “What are the key pricing provisions in the Acme contract?” After two searches, it has clauses on rate schedules, discount tiers, and annual escalation. It searches a third time with a different query and gets back the same escalation clause it already found. At that point, it recognizes it’s seeing diminishing returns — new searches are surfacing the same material — and stops.
With traditional RAG, the developer needs to design the retrieval strategy at build time. With Agentic RAG, the agent designs its retrieval strategy at query time.
Where Agentic Search Breaks
It’s tempting to look at the differences above and conclude that Agentic Search is always superior. While theoretically true—practically, it turns out not to always be. Indeed, each component of Agentic Search can actually be quite hard.
To figure out why, let’s look at the three parts of the Agentic Search pipeline in closer detail.
Hard Problem 1: Query Planning
Query planning fails in two ways: over-decomposition and under-decomposition.
Over-decomposition wastes resources on queries that didn’t need it. Under-decomposition misses information that required separate lookups.
Over-Decomposition: Agent issues too many sub-queries, wasting resources.
Under-Decomposition: Agent misses an important facet, leading to a confident yet incomplete answer.
Hard Problem 2: Iterative Retrieval
Iterative retrieval is where the agent searches again based on what was found (or wasn’t found). The failure modes here can be subtle and expensive.
Query drift: Each refinement may follow the retrieved results a bit too much instead of the original intent. The steps feel locally reasonable, but the trajectory ends up wandering:
Wrong hop: Multi-hop queries chain information across searches: the output of one search informs the next. If the agent takes a wrong branch, every subsequent hop ends up building on the wrong foundation:
Hard Problem 3: Self Evaluation
Throughout the search process, the agent needs to determine when / where to stop. This is an advanced reasoning capability and arguably the hardest thing to get right with Agentic Search.
Premature stopping: “I found relevant information” and “I found all the relevant information” are very different conditions, and the model tends to conflate them.
Inability to stop: The inverse—the agent continuing to search even when it already has comprehensive coverage, because it can’t assess its own completeness.
In all of these failure modes, the fundamental issue is the agent’s “intuition” and a deep understanding of the underlying corpus.
The typical fix is to encode these heuristics in the prompt: “always decompose multi-entity queries,” “stop after three consecutive searches with no new results,” and so on. This can work until the corpus grows or query patterns shift, at which point you’re back to playing whack-a-mole with edge cases.
Ultimately, prompts end up being brittle for encoding these heuristics or “intuition”. Rather, they belong in the weights—learned from your data, not hand-written against it.
Getting Agentic Search Right
The most effective solution to the failure modes above is to train an RL-based retrieval policy on your specific corpus. The retrieval model is trained to learn when to decompose, how to reformulate, and when to stop from real query patterns rather than hand-written rules.
However, most engineering teams don’t have the bandwidth to train their own models. Even if you’re in this camp, your agent can still do better. Here’s how to diagnose and improve your Agentic RAG solution.
Evaluating failures
Surprise surprise, evals: the first step is knowing which failure mode is hurting you. Build evals around each failure mode mentioned above:
- Query planning: take a set of known multi-part questions and check whether the agent issues the right number of searches. Are simple questions getting over-decomposed? Are multi-entity queries getting squashed into one?
- Iterative retrieval: compare each search query back to the original question. If query 3 shares no keywords with the original question, you have drift. If the same passages keep coming back across searches, you have redundancy.
- Self-evaluation: for questions where you know the complete answer set, check coverage. Did the agent find 3 out of 12 relevant contracts and stop? Did it keep searching after it already had everything?
For query planning and iterative retrieval, an LLM-as-judge works well—give it the original query and the agent’s search trace, and have it flag over-decomposition, drift, or redundancy. Self-evaluation is harder to judge automatically because you need ground-truth coverage data (how many relevant documents actually exist for a query). For that, start with a small set of queries where you’ve manually annotated the complete answer set, and measure recall against it.
None of this needs to be super elaborate. A spreadsheet of 50 representative production queries with expected behavior will likely surface your dominant failure mode quickly.
What to focus on
Once you know where you’re failing, the highest-leverage fixes map directly to the three capabilities:
For query planning, the most common fix is few-shot examples in your system prompt that demonstrate correct decomposition for your domain. Show the model what a 1-search query looks like vs. a 3-search query. This is fragile but works as a starting point.
For iterative retrieval, anchor each refinement back to the original query. One effective pattern is to include the original question in every search call—not just the refined sub-query—so the retrieval system can weigh both the original intent and the refinement.
For self-evaluation, give the agent explicit stopping criteria rather than relying on its judgment. For exhaustive queries (“all contracts,” “every vendor”), tell it how many documents the corpus has, what the shape of the corpus looks like, etc. so that the agent has more signposts to work off of.
Or let the retrieval system handle it
The fixes above work, but they’re exactly the kind of prompt-level heuristics that break as your corpus and query patterns evolve.
The alternative is to move the agentic retrieval out of your agent code entirely. Instead of your agent orchestrating searches, you can call a retrieval service that handles decomposition, multi-hop search, and completeness assessment internally:
import { generateText } from "ai";import { anthropic } from "@ai-sdk/anthropic";import { createSearchTool } from "@charcoalhq/ai-sdk";
const { text } = await generateText({ model: anthropic("claude-sonnet-4-6"), tools: { search: createSearchTool({ namespace: "my_namespace" }), // ... other tools }, prompt: "Some hard question requiring multi-hop, comprehensive search",});Your agent is then able to focus on reasoning over complete, cited results—not on managing a search loop. The planning, iterating, and self-evaluation all happen inside the retrieval service, trained on your specific corpus via RL.
This is what Charcoal is built to do. If you’re building agents that need to reason across large document collections, come talk to our engineering team!